セミナー動画
※2020年12月9日に開催したオンラインセミナーを再編集したものを配信しています
動画の内容はこちら
AIと法務
AIと法務は、一見するとあまり関係がなさそうですが、決してそのようなことはありません。今後、AIに関する法律問題は、増加してくると予想されるからです。
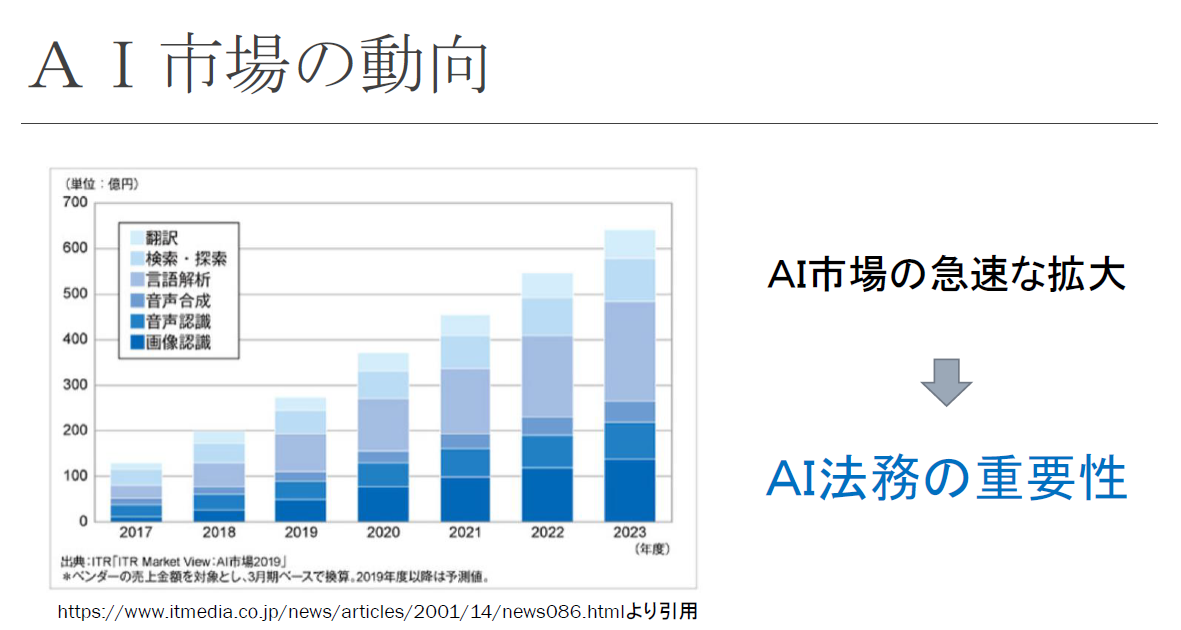
こちらのグラフは、今後のAI市場の動向を予想したものです。今後、AI市場は右肩上がりに拡大していくことが予想されています。市場が拡大すれば、AIに関する法律問題が発生する頻度も増えていくと考えられます。
AIで法律問題が発生しやすい要因
AIには、法律問題が発生しやすい3つの要因があります。
1.莫大な投資がなければ成果物が生まれない
AIの開発には、多額の資金が投じられることが一般的です。大きな資金が動くビジネスでは、大きな法律トラブルも起きがちです。
2.成功すれば得られるリターンが大きい
画期的なAIの開発に成功した場合、大きなビジネスチャンスにつながり、その結果、開発に携わっていた企業に大きなリターンをもたらすことが多々あります。このようなリターンを共同で開発を進めていた企業の一方が独占しようとしたり、リターンを得る権利をめぐってもめたりすることで、そこに法律トラブルが生まれてしまいます。
3.成果物が完成するまで目標達成度が分からない
後ほど詳しく説明しますが、AIの開発は、実際に完成するまで、どの精度が上がったか、つまり、プロジェクトの目標達成度を正確に予想することが難しい問題があります。最後まで結果が見えないというところが、AIの開発に関して法律トラブルが発生しやすい大きな原因の1つです。
このセミナーのテーマ
このセミナーの大きなテーマは、法務担当者の方だけではなく、プロジェクトマネジメントの方やデータサイエンティストの方、システムエンジニアとして開発に携わる方が、AI開発にかかわる法律問題の発生を防ぐためにどのようにかかわることができるかについてです。
このセミナーでは、AI開発プロジェクトの成果物についてベンダー(特にAIベンチャー)がユーザーと適切に知財交渉を進めるためのノウハウと、ベンダーがユーザーからプロジェクトマネジメント上の法的責任を問われないための留意点についてお伝えしています。
ぜひ、法務担当者の方だけではなく、プロジェクトマネジメントの方やデータサイエンティストの方、システムエンジニアといったAI開発プロジェクトにかかわるすべての方にご参考にしていただければと思います。
知財交渉の視点から-ベンダーが有利な交渉を進めるために-
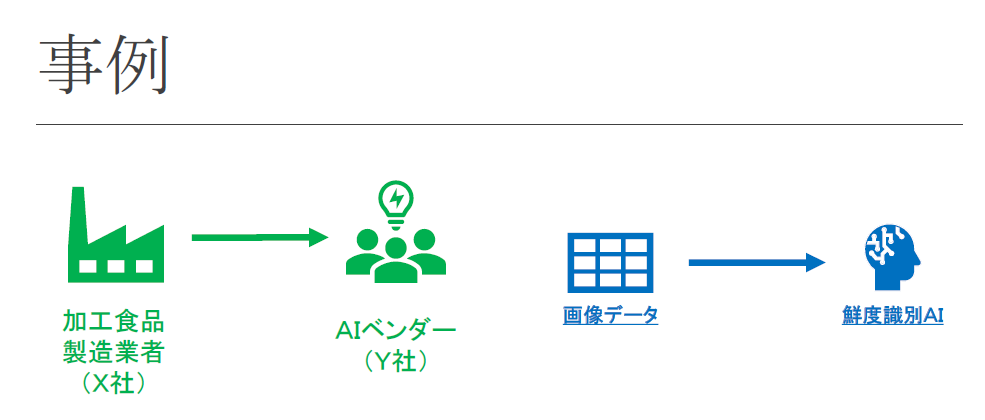
事例の概要
X社について
X社は、缶詰や冷凍食品などの加工食品を手掛けている大手の食品メーカーです。
これまで、缶詰や冷凍食品に使用する野菜・魚・肉などの食材の鮮度は、人の手で選別していました。ただ、鮮度の正確な選別には目利きのノウハウが必要であるうえに、原材料の1つ1つをチェックしなければならないことから、多数の人手が必要でした。
そこで、原材料の選別作業を、AIによって代替できないかと考えています。これによって、人員を減らすことができ、コスト削減につながることを期待しています。
Y社について
Y社は、画像認識技術、特にCNN(畳み込みニューラルネットワーク)について研究をしていた学生らが集まって設立したベンチャー企業です。現在、設立から3年目で、これまで、様々な業種において高精度な画像認識技術を開発してきた実績があり、メディアにも取り上げられていました。
X社からY社への開発依頼
X社は、今回のAI開発を、メディアを通じて知ったY社に委託することにしました。
Y社は、X社に企画の概要を説明したうえで、「今回の案件は低予算で進めたいと考えている。」と説明しました。
AI開発のプロセス
プロセス1.
X社からは、これまでの食品加工の際に製造工程内で自動撮影された大量の食材の画像データを保有していました。画像データは、鮮度の度合いに応じてすでに分類されていました。
プロセス2.
Y社は、機械学習に明らかに適さない画像を選別するAIを開発していたことから、そのAIにより、機械学習に明らかに適さない画像の削除を実施しました。
プロセス3.
プロセス2だけでは、機械学習に適さない画像が多く残存していたことから、Y社のスタッフの目で画像をチェックして、選別作業を実施しました。それとともに、機械学習の精度を上げるための分類作業も実施しました。
プロセス4.
PoCを実施して、学習条件の調整やデータの分類方法の見直しといった作業を実施しました。
プロセス5.
その後、開発プロセスに移行して本格的な機械学習を実施して、学習済みモデルを完成させました。なお、機械学習には、汎用的なCNN(畳み込みニューラルネットワーク)を使用しました。
プロセス6.
実際にX社の工場においてAIを組み入れたシステムを試行したところ、X社が期待しているレベルの精度を達成することができました。
成果物
プロセスの中で、食材の画像の選別や分類を実施することで完成したデータセットと、機械学習によって完成した学習済みモデルが、成果物として生じました。
Y社が目指したい知財交渉の目標
データセット
Y社としては、開発費用を低額におさえる代わりに、成果物であるデータセットを他の食品関連メーカーの案件に転用したいと考えています。それによって、今回のAI開発で培ったノウハウを今後も活かしていきたいと考えています。
学習済みモデル
Y社としては、開発費用を低額におさえる以上は、学習済みモデルやその再利用モデル(追加学習で作成したモデル)をX社が自由に転売することを制限したいと考えています。特に、X社が、今後Y社の進めたいAI開発案件の競合になることは避けたいと考えています。
AI開発のプロセスについて
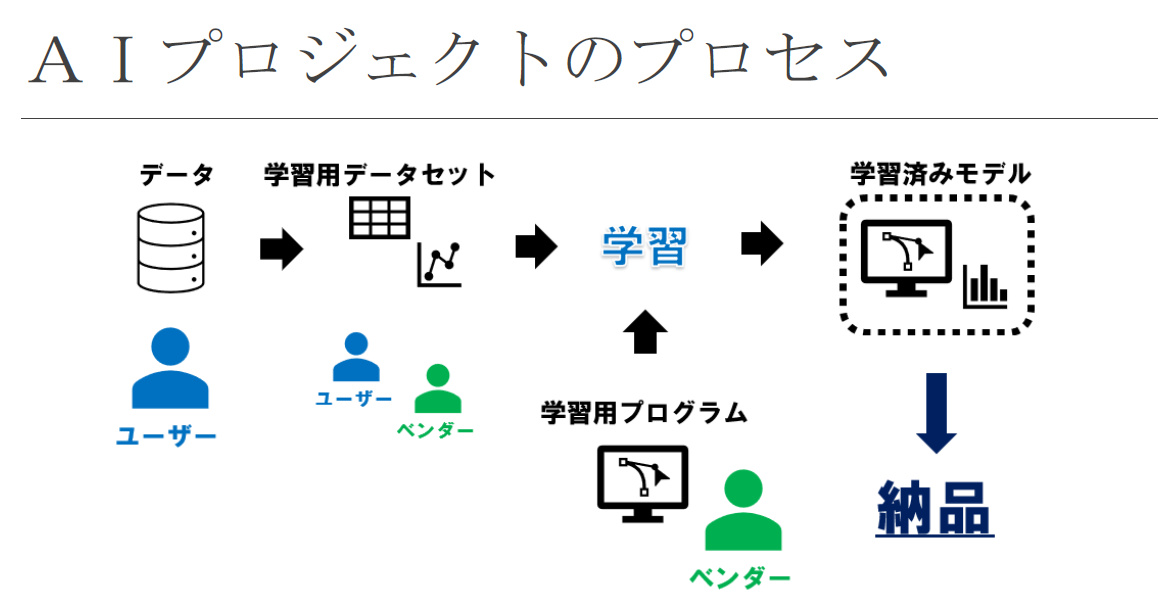 上の図は、AI開発のプロセスを示したものです。
上の図は、AI開発のプロセスを示したものです。
AIの開発は、学習に適さないデータも含めた多数のデータが含まれる状態から不要な画像の削除や分類、データの加工処理などを実施して、機械学習に適したデータセットを完成させるところから始まります。
そして、そのデータセットを学習用プログラム(ニューラルネットワーク)に投入して、学習済みモデルを完成させることが、基本的な流れです。
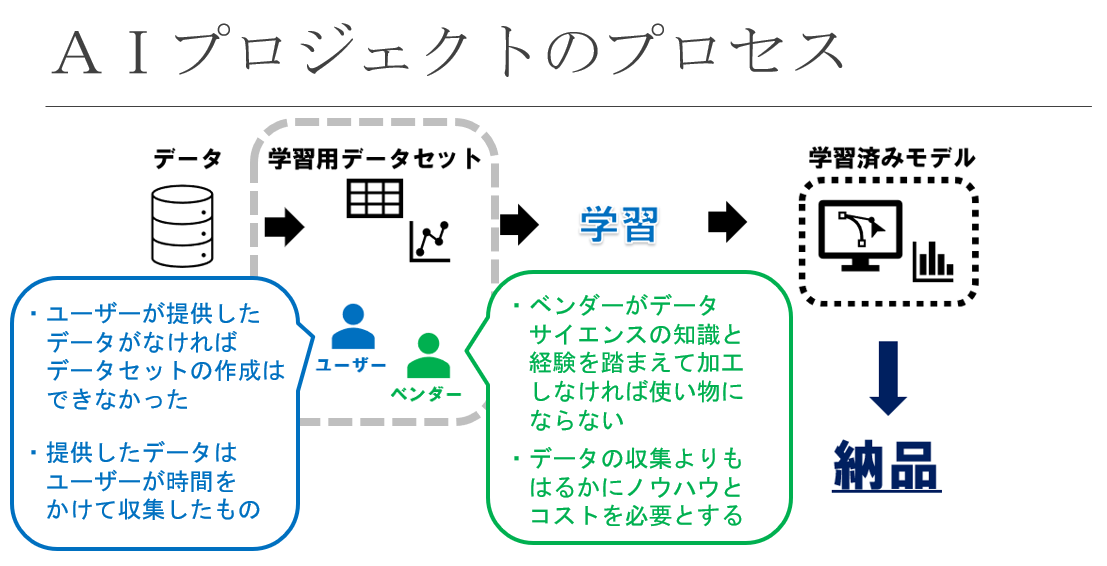
まず、データセットの知財交渉について考えます。データセットについては、ユーザーとベンダーがそれぞれの立場から自らに有利な主張を行い、平行線をたどってしまうケースがあります。なぜなら、ユーザー・ベンダーのそれぞれが、データセットが自らの貢献によって完成した成果物であると認識し、両者の考えにズレが生じてしまうことが多々あるからです。ユーザーは、長い時間をかけて収集したデータを提供することでデータセットの完成に大きく貢献したと考えます。一方、ベンダーは、データサイエンスの知識と経験を踏まえてそのデータに処理を施すことによって、データを使えるもの(データセット)にしたと考えます。このような認識のズレが、対立を生む要因になってしまいます。

次に、学習済みモデルの知財交渉について考えます。学習済みモデルについても、ユーザーとベンダーがそれぞれの立場から自らに有利な主張を行い、平行線をたどってしまうケースがあります。ベンダーは、学習済みモデルは自らのノウハウと労力によって完成させたものであるから、今後も自らのビジネスに活かしたい、少なくともユーザーによる他ビジネスへの転用や販売を制限したいと考えることがしばしばあります。一方で、ユーザーは、自らが委託料を支払って完成させたものであることや、そもそも企画のアイデアはユーザーが持ち込んだものであること、機械学習に必要なデータは自らが用意したことなどを理由に、他案件への転用や販売を含めた自由利用をベンダーに認めさせたいと考えることがしばしばあります。このような考え方のズレが、対立を生む要因になってしまいます。
ベンダーがユーザーとの交渉に失敗するケースとは
ベンダーがユーザーとの交渉に失敗する原因として多いのが、ユーザーとベンダーとの間で交渉力に格差があるケースです。交渉力の格差が生じる要因として、2つのことが挙げられます。
法務のノウハウに対する格差
1つは、法務のノウハウの格差です。特に、ユーザーが大企業である場合、法務・知財に精通した社員が在籍していることが通常であるため、ベンダーが成長段階のベンチャー企業の場合には大きな格差が生じます。
もっとも、このような法務のノウハウの格差であれば、ベンダー側も法務の専門家との連携体制を構築するなどの方法で格差を是正していくことが可能です。
企業規模や知名度などのビジネス面での格差
もう1つは、企業規模や知名度などのビジネス面のノウハウの格差です。ベンダーとしては、今後の大手ユーザーとの良好な関係の継続を意識して、結果として有利な交渉を進められないことが多々あります。
このような状況においてもベンダーが交渉を対等に(あるいは対等にできる限り近い形で)進めていくための方法の1つとして、他ベンダーと差別化できるような自社のAI開発ノウハウの高さをアピールすることが考えられます。ただ、ユーザーの多くはAIの技術面での知識に精通していないことから、このようなアピールをしても、「どこが他ベンダーよりも優れているのか」をあまり理解できないことがよくあります。そのために、このようなアピールがあまり功を奏さないことはよくあることです。
そのような中でベンダーが交渉を対等に(あるいは対等にできる限り近い形で)進めていくための方法として、「フェアな交渉を求めるための合理的な説得」をユーザーに対して尽くすことが考えられます。ユーザーが大企業の場合には特に、「取引相手にアンフェアな条件を押し付けることは避けなければならない」という意識があることが一般的です。ベンダーとしては、フェアな交渉のあり方についてうまくユーザー側に伝えて、アンフェアな条件提示を避けるように暗に促すことによって、交渉を有利に進めていくことが考えられます。
では、フェアな交渉のあり方についてうまく伝えるためには、どのような知識が必要でしょうか。実は、ここでも、法律的な知識が重要になってきます。
交渉を有利に進めるために
それでは、ユーザーとの交渉を有利に進めるために、どのような法律知識が必要になるのでしょうか。ここから、詳しく説明していきたいと思います。
データセットの保護にかかわる知的財産法のルールについて
データの保護に関する法律とは
データの保護については、不正競争防止法にルールが定められています。不正競争防止法に基づいてデータを保護するルールには、次の2つがあります。
(1) 営業秘密としてデータを保護するルール
(2) 限定提供データとして保護するルール
では、2つのルールについて、ここから詳しく検討していきます。
営業秘密としてデータを保護するルール
まず、営業秘密から見ていきましょう。不正競争防止法は、他の企業が有していないビジネス上有用な情報を営業秘密として管理している場合に、その情報を保護するルールを定めています。
例えば、ユーザーが営業秘密として保護されるデータをベンダーに提供した場合は、ベンダーがその情報をユーザーから受注した案件以外の目的に転用したり、他の企業に提供したりすることが不正競争防止法で制限されます。
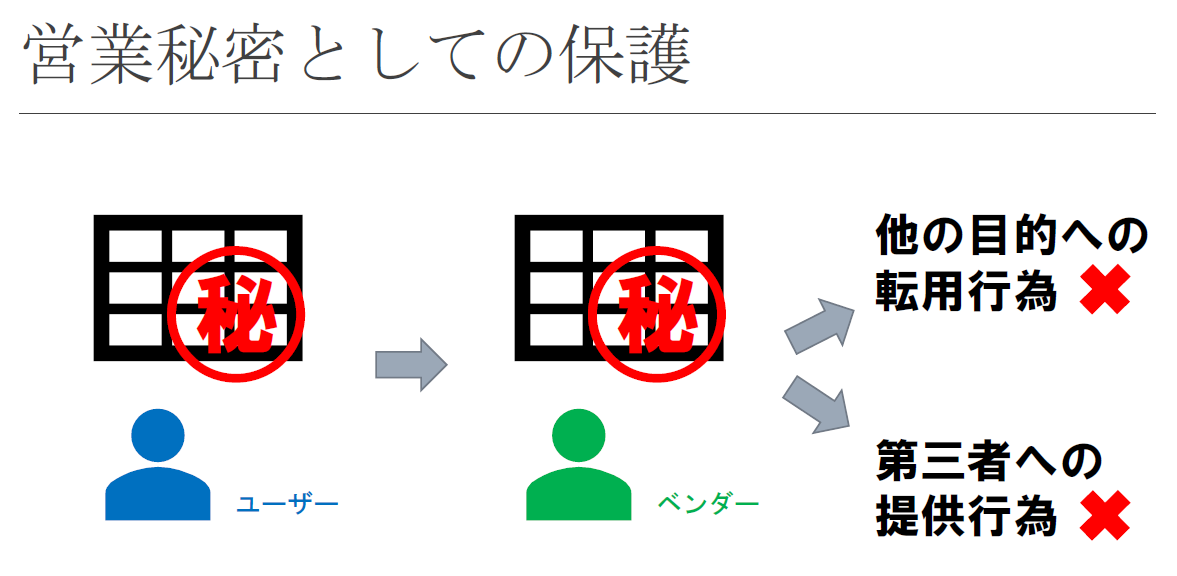
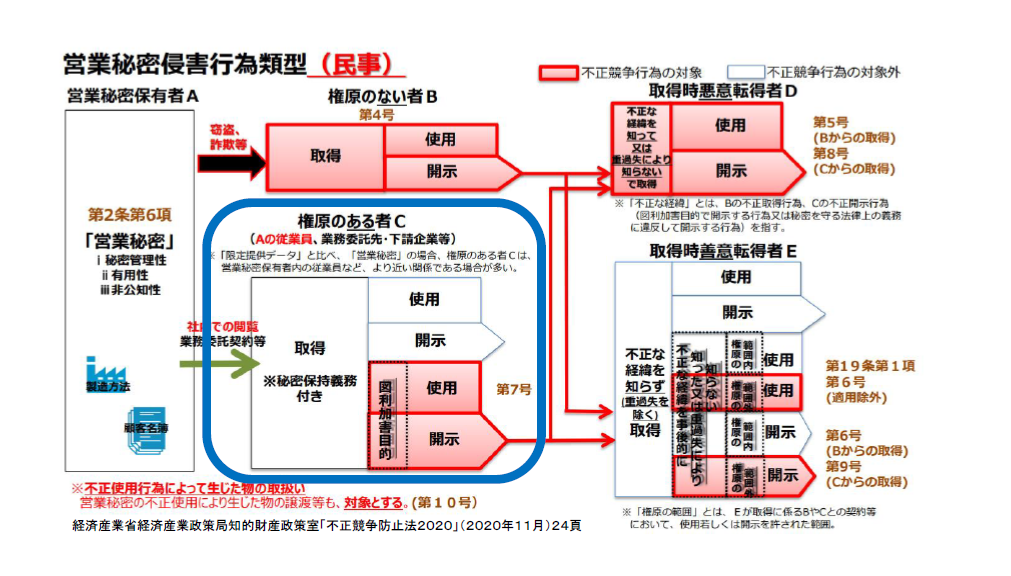
下の図は、不正競争防止法によって営業秘密が保護される範囲を示したものです。赤色で塗られた部分は不正競争防止法で規制される部分、それ以外の部分は規制の対象外とされる部分です。ユーザーとベンダーとの関係においては、通常、青色の線で囲まれた部分が問題になります。
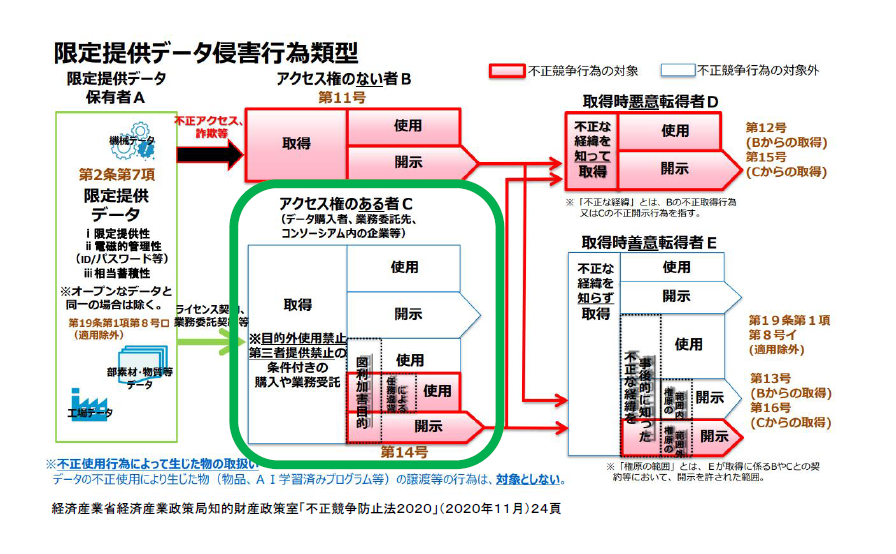
限定提供データとしてデータを保護するルール
次に、限定提供データについて見ていきましょう。限定提供データの保護は、不正競争防止法の改正によって新たにできたルールです。ビッグデータの中には、営業秘密とはいえないものの、ビジネス上の有用性があるものがあります。そのようなビッグデータについて保護対象にするのが、限定提供データの保護に関するルールです。
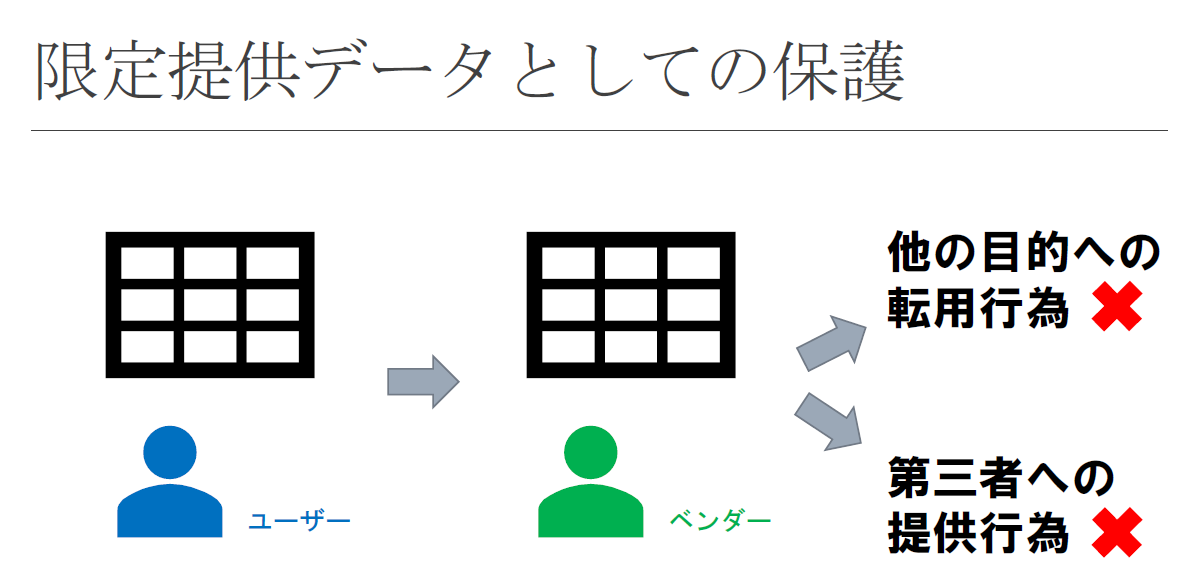
下の図は、不正競争防止法によって限定提供データが保護される範囲を示したものです。赤色で塗られた部分は不正競争防止法で規制される部分、それ以外の部分は規制の対象外とされる部分です。ユーザーとベンダーとの関係においては、通常、緑色の線で囲まれた部分が問題になります。
不正競争防止法から考える交渉を有利に進めるためのポイント
ここまで説明した営業秘密と限定提供データのルールを分析すると、不正競争防止法には、データの保護について以下の3つの視点があることが分かります。
(1)データに価値を生んだ人は保護されるべきという視点
(2)価値を生むためにコストやノウハウを投じた人は保護されるべきという視点
(3)保護される範囲は、自分が不利益を負ったり、他人がそこから不正な利益を得たりしない範囲にとどまるものであるという視点
それでは、営業秘密と限定提供データのそれぞれについて、不正競争防止法によって保護される要件を見ながら、実際にこのような3つの視点がどこに現れているのかについて見ていきましょう。
営業秘密について
データが営業秘密として不正競争防止法で保護されるためには、秘密管理性・有用性・非公知性の要件を満たさなければなりません。このうち、有用性とは、簡単にいえば、ビジネスに何らか役立つデータであるという意味です。また、非公知性とは、簡単にいえば、他の人には簡単に手に入らないデータであるという意味です。

他の人が簡単に手に入らないデータは、そのデータの価値を生んだ人(簡単に手に入らないようなものにした人)が何らかのコストやノウハウを投じていることが一般的です。そうすると、そのようなデータを秘密として管理している人を保護すれば、結果的に、データに価値を生んだ人、かつ、その価値を生むためにコストやノウハウを投じた人が保護されることになります。
(1)データに価値を生んだ人は保護されるべきという視点
(2)価値を生むためにコストやノウハウを投じた人は保護されるべきという視点
限定提供データについて
データが限定提供データとして不正競争防止法で保護されるためには、限定提供性・電磁的管理性・相当量蓄積性の要件を満たさなければなりません。このうち、相当量蓄積性とは、データがビジネスに役立つレベルになる程度に蓄積されていることを意味します。

限定提供データを構成する個々のデータは、ビジネス上の価値があるものとは限りません。個々のデータを集積することで、はじめて限定提供データとしての価値が生まれます。例えば、A月B日15時の大阪市でC地点で雨が降っていたかどうかの情報にほとんど利用価値はありませんが、1000地点で1年間にわたって毎時の降雨情報が記録されたデータは、ビジネス上の利用価値が生まれます。
そして、ビジネス上の価値が生まれる程度にまで個々のデータを集積するためには、コストやノウハウを投じなければなりません。限定提供データを保護するということは、データに価値を生んだ人、かつ、その価値を生むためにコストやノウハウを投じた人を保護することにつながります。
(1)データに価値を生んだ人は保護されるべきという視点
(2)価値を生むためにコストやノウハウを投じた人は保護されるべきという視点
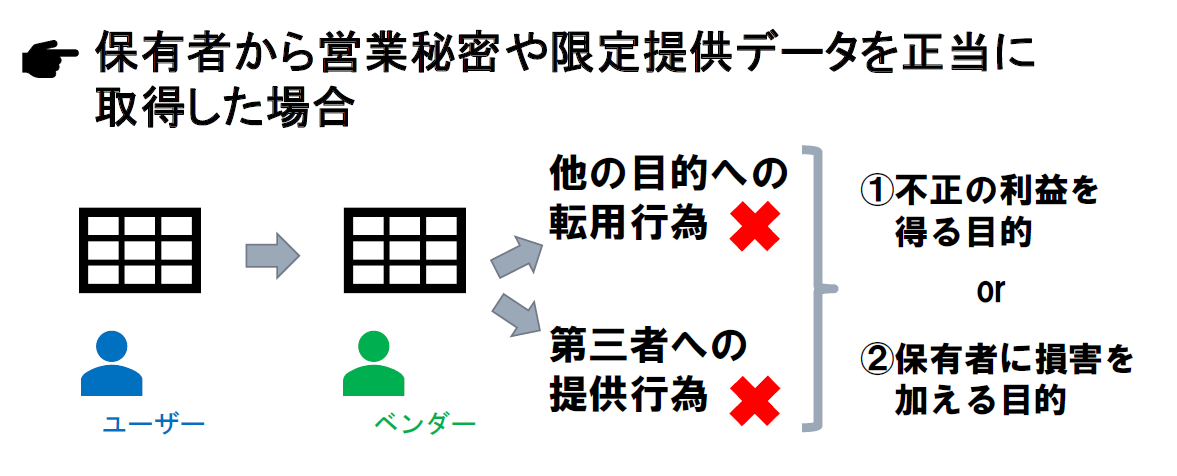
ベンダーの行為が不正競争防止法違反になるケース
営業秘密や限定提供データをユーザーがベンダーに対して正当に取得させた場合、ベンダーによる転用や第三者提供はすべてが不正競争防止法違反になるわけではありません。このようなケースにおいて転用や第三者提供が不正競争防止法違反となるのは、ベンダーに不正の利益を得る目的があった場合や、保有者(ユーザー)に損害を加える目的があった場合に限定されます。
(3)保護される範囲は、自分が不利益を負ったり、他人がそこから不正な利益を得たりしない範囲にとどまるものであるという視点
データセットについて有利な交渉を進めるためには
以上のことを踏まえると、データセットについて有利な交渉を進めるためには、次の2つの観点を強調すればよいという考え方を導くことができます。
(1)ベンダーがコストやノウハウを投じなければデータセットには価値は生まれなかった
(2)ベンダーがしたいデータセットの転用行為はユーザーに不利益を与えるものでもベンダーの不正な利益につながるものでもない
では、以上の観点を踏まえて、はじめに取り上げた事例を検討してみましょう。
事例についての検討(データセット編)
Y社としては、開発費用を低額におさえる代わりに、成果物であるデータセットを他の食品関連メーカーの案件に転用したいと考えています。それによって、今回のAI開発で培ったノウハウを今後も活かしていきたいと考えています。
さて、ユーザーとうまく交渉を進めていくためにどのような視点を踏まえればよいのかについて、考えていきましょう。
1.ベンダーがコストやノウハウを投じなければデータセットには価値は生まれなかった
まずは、ベンダーがデータセットを作成するためにどのようなコストやノウハウを投じたかについて、検討していきます。

ユーザーが提供したデータの集積は、そのままでは機械学習に適さない場合が一般的です。ベンダーが、ユーザーの意見も踏まえながら、データサイエンスの知識をもって丁寧に画像のすみ分け・適切なグループ化・データオーグメンテーションなどの加工処理を施すことによって、はじめて使い物になるデータセットが完成します。このような作業に、ベンダーは、多大な労力とノウハウを投じたということができます。
ベンダーにとって、データセットを作成するために多大な労力とノウハウを要することは「常識」かもしれませんが、一方で、ユーザーにとっては「常識」ではありません。そのため、ユーザーに多大な労力とノウハウを投じたと説明するだけでは、なかなかユーザーの理解を得ることはできません。ユーザーに対してベンダーがどのような労力やコストを投じたのかについて明瞭に説明するためには、AIプロジェクトの技術面に理解のある担当者が交渉の場に同席することが重要になります。
2.ベンダーがしたいデータセットの転用行為はユーザーに不利益を与えるものでもベンダーの不正な利益につながるものでもない
たとえユーザーに対してコストやノウハウを投じたことを合理的に説明しても、ベンダーがデータセットを自由に転用・第三者提供することに対してユーザーが納得するとは限りません。ユーザーの納得を得られない場合には、ユーザーとの落としどころをみつけるための交渉を検討しなければなりません。
例えば、本事例においてユーザーがベンダーによるデータセットの転用などに抵抗を覚える理由として、データセットの中に鮮度を識別するユーザー独自のノウハウ(野菜の鮮度を色や形状から識別するノウハウなど)が含まれていることが考えられます。そうであれば、ノウハウに基づいてデータを分類した部分を削除して、そのようなノウハウが含まれないデータセットに限って転用などを認めるように交渉することが考えられます。
また、ユーザーの競合である加工食品業界での利活用はしないことを条件に、データセットの転用などを認めてほしいことを交渉する方向性も考えられます。
交渉に際しては、「ビジネス」「法務」「AI技術」それぞれの知識をもつ人が連携して、臨機応変に交渉スタンスを検討することが重要です。
学習済みモデルの保護にかかわる知的財産法のルールについて
次に、学習済みモデルについて、知的財産権をベンダーが主張する方法について検討します。学習済みモデルは、ベンダーが主導で進める機械学習によって生成されるものであることから、知的財産権をベンダーがユーザーに対して主張できないのでしょうか。
学習済みモデルは著作権法で保護されるか
まず、学習済みモデルは著作権法で保護されるかについて検討します。そもそも、学習済みモデルは、著作権法で保護される「著作物」に該当するのでしょうか。
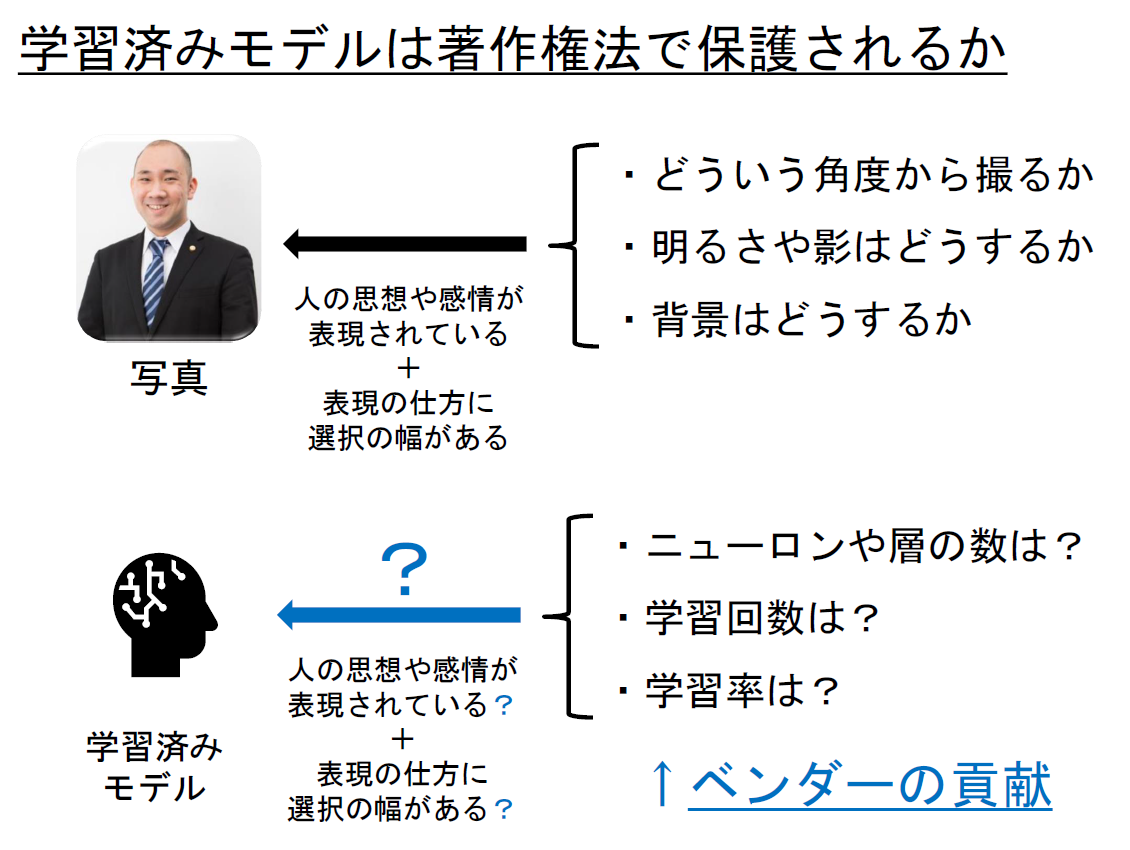
著作物に該当するためには、「思想又は感情を創作的に表現したもの」でなければなりません。そのためには、(1)人の思想や感情が表現されていることや、(2)表現の仕方に選択の幅があること(創作性)が必要です。
では、学習済みモデルは、これらの要件を満たすのでしょうか。学習済みモデルが著作物に該当するかどうかを検討する際に参考になるのが、写真の著作物性です。
写真が著作物であることについては、おおむね異論はないことと思います。ただ、写真は、絵画とは異なり、人の手ではなく、機械によって生成されるものです。それではなぜ、写真は著作物といえるのでしょうか。
写真は、撮影者の力量によって良し悪しが変わってきます。同じ被写体であったとしても、撮影角度や明るさ、背景の選択などの様々な要素によって、出来栄えが変わるものです。そして、このような要素は、最終的には人が選択するものです。このような選択に、人の思想や感情が表現されているということができます。また、撮影角度や明るさ、背景の選択などは無限にありますので、表現の仕方には選択の幅があると考えることもできます。以上の理由から、写真は著作物であると評価することができます。
では、学習済みモデルの場合はどうでしょうか。学習済みモデルの場合も、ニューロンや層の数、学習回数、学習率といった学習条件の設定は無限にあり、(少なくとも現状においては一般的に)人の手によって設定されます。この点を重視すれば、学習済みモデルには人の思想や感情が表現されていて、かつ、表現の仕方に選択の幅があるということができます。
ただし、このような考え方に対しては異論があるところです。まず、どのような学習条件を設定することによってどのような成果が生まれるのかを人が事前に予想することが難しいにもかかわらず、人の思想や感情が表現されていると本当にいえるのかどうかは、争いになりえます。また、精度の高いAIを生成することのできる学習条件は似通ったものになるため、表現の仕方に選択の幅があると本当にいえるのかどうかも、争いになりえます。
学習済みモデルが著作物に該当するかどうかは争いがありますが、ベンダーの立場からは、学習済みモデルは著作物であることを前提にした交渉をすべきです。ただし、実際に紛争になった際に著作物性が否定されうることを踏まえて、著作権法の適用が否定されたとしても著作権法によって保護される場合と実質的に同様となるような利用条件を当事者間の合意によって定めておくことが適切です。
ベンダーの著作物であることを主張するために
学習済みモデルが著作物に該当するとした場合は、その著作者がだれであるかが問題になります。
学習済みモデルがユーザーの提供したデータによって生成されたものであることを理由に、学習済みモデルの著作者はユーザーである、あるいは、ユーザーとベンダーの共同著作物であるという主張をされた場合、ベンダーとしてはどのように反論すればよいでしょうか。
ここで、ユーザーに対する反論の根拠となりうるのが、著作権法第30条の4の規定です。
著作権法
(著作物に表現された思想又は感情の享受を目的としない利用)
第30条の4 著作物は、次に掲げる場合・・・には、その必要と認められる限度において、いずれの方法によるかを問わず、利用することができる。ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
・・・(中略)・・・
二 情報解析(多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行うことをいう。第四十七条の五第一項第二号において同じ。)の用に供する場合
・・・(以下省略)・・・
著作権法第30条の4の規定は、機械学習のために著作物が含まれるデータを(著作権者の許諾なく)利用することを、広く許容しています。そのことから考えると、著作権法の観点からは、データを提供したことを理由に直ちに著作権法上の保護を享受できるものではないということができます。
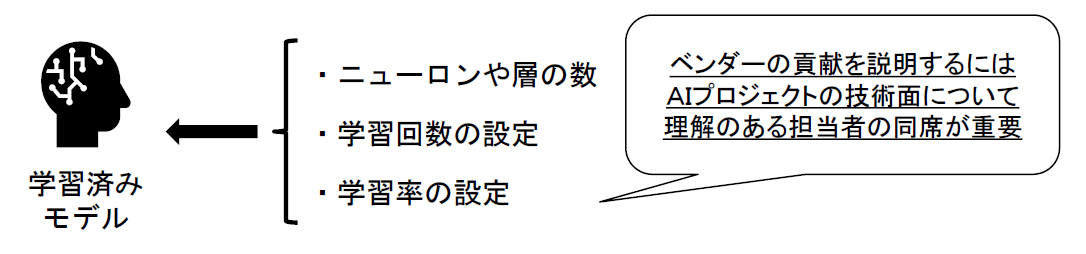
一方で、ベンダーは、ニューロンや層の数、学習回数、学習率といった様々な学習条件を選択することによって、学習済みモデルの著作物性を肯定することにつながる貢献を大いにしています。
これらの観点を踏まえれば、学習済みモデルが著作物であることが認められるならば、その著作者はベンダー単独であると考えることが適当です。
【補論】学習済みモデルは特許法で保護されるか
理論的には、学習済みモデルについて特許を取得する余地があります。
もっとも、学習済みモデルの特許出願には、ハードルがあります。特許出願においては、前提条件がある程度変わっても同様の効果を発揮することのできる学習条件を示すことが必要です。ただ、機械学習の前提条件や学習方法が少し変わるだけで、完成する学習済みモデルは大きく変化してしまうことが一般的であるため、このような学習条件を示すことには大いにハードルがあります。そのため、学習済みモデルについて特許を取得することは、容易ではありません。
学習済みモデルについて知財交渉を進める際には
以上の観点を踏まえれば、学習済みモデルについて、ベンダー側に有利に知財交渉を進めるためには、次の2つの観点を意識すればよいといえます。
(1)学習済みモデルはベンダーの著作物であるという考え方を交渉の出発点にする
(2)学習済みモデルがベンダーの著作物としてどこまで保護されるかについては考え方が確立されていないことから利用条件を明確に合意する方向で進める
では、ここからは、はじめに取り上げた事例を検討してみましょう。
事例についての検討(学習済みモデル編)
Y社としては、開発費用を低額におさえる以上は、学習済みモデルやその再利用モデル(追加学習で作成したモデル)をX社が自由に転売することを制限したいと考えています。特に、X社が、今後Y社の進めたいAI開発案件の競合になることは避けたいと考えています。
さて、ユーザーとうまく交渉を進めていくためにどのような視点を踏まえればよいのかについて、考えていきましょう。
1.学習済みモデルはベンダーの著作物であることを前提にした交渉を求める
まずは、ベンダーが学習済みモデルの生成のためにどのような貢献をしたかについて的確にユーザーに説明して、学習済みモデルの著作者はベンダーであることへの理解を得ることが重要です。そのためには、AIプロジェクトの技術面について理解のある担当者が交渉の場に同席することが必要になります。
2.お互いに納得することのできる落としどころを見つける
もっとも、先ほど説明したように、著作権の帰属について合意するだけでは不十分であり、仮に著作権法による保護を受けられなかった場合を前提に、学習済みモデルの利用条件について明確な合意をしておくことも重要です。利用条件の合意を目指すうえでは、ただベンダー側にとって一方的に有利な条件を提示することだけではなく、ユーザー側の利益にも歩み寄る姿勢を見せることも大切です。例えば、ベンダーの転用を認める代わりにユーザーの自由利用もある程度認める提案など、ベンダーが目指したい方向性を踏まえつつ、臨機応変に譲歩をする姿勢も必要です。
学習済みモデルについて有利に交渉を進めるうえでも、やはり、「ビジネス」「法務」「AI技術」それぞれの知識をもつ人が連携して、臨機応変に交渉スタンスを検討することが重要です。
プロジェクトマネジメントの視点から-ユーザーから法的責任を問われないために-
事例の概要
企画の概要
X社は、缶詰や冷凍食品などの加工食品を手掛けている大手の食品メーカーです。
これまで、缶詰や冷凍食品に使用する野菜・魚・肉などの食材の鮮度は、人の手で選別していました。ただ、鮮度の正確な選別には目利きのノウハウが必要であるうえに、原材料の1つ1つをチェックしなければならないことから、多数の人手が必要でした。
そこで、原材料の選別作業を、AIによって代替できないかと考えています。これによって、人員を減らすことができ、コスト削減につながることを期待しています。
X社は、AIベンチャーであるY社に、AIの開発を委託しました。
法律トラブル1
完成したAIの精度は90%程度で、10%程度の誤判定があるために、実際に現場で使うことができないものでした。
→ AIの精度が低いことについて、ユーザーから法的責任を問われてしまいました。
法律トラブル2
法律トラブル1の問題が発生した後、Y社は、AIの精度を高めるために、画像データを分類するカテゴリを従来よりも多いパターンに細分化して、それぞれのカテゴリに分類しうる可能性をAIでパーセンテージ評価し、その結果を総合的に分析することで鮮度の良し悪しを判定する手法を新たに採用することにしました。その結果、99%の高精度を達成することができ、現場で使うことにおおむね支障がない程度になりました。
→ ユーザーに追加費用を求めたところ、(今回の件はベンダーの当初の開発プロセスに問題があったとして)支払を拒否されました。
検討事項
それぞれのユーザーの主張について、どのような観点で反論を検討していけばよいのでしょうか。
一般的なシステム開発とAIシステム開発は何が違うのか
今回発生した法律トラブルについて検討する前提として理解しておかなければならないのが、一般的なシステム開発とAIシステム開発の違いです。
一般的なシステム開発の場合は、要件定義どおりに仕様設計を進めてそのとおりにプログラミングをすれば、あらかじめ意図したとおりのシステムを完成させることができます。システムの挙動に問題がある場合、開発プロセスのどこかの段階で人為的なミスがあったことが明確です。
一方で、AIシステム開発の場合、実際に成果物である学習済みモデルが完成するまで、それがあらかじめ期待していたレベルに達しているのかどうかを予想することが難しいです。つまり、AIシステム開発の場合、完成を保証することができません。
一般的なシステム開発は、建築と似ています。建築も、発注者の注文内容を踏まえて設計書を作成し、そのとおりに進めていくことで、発注者が意図しているものが完成するからです。
一方、AIシステム開発は、建築よりも、むしろ、医師の診療行為と似ています。例えば、病気になってクリニックを受診した場合を想定してみてください。よく、医師から「お薬を出しておきますので2週間後にまた来てください。お薬の効きが悪ければ、別のお薬に変えてみましょう。」というアドバイスを受けることがあります。治療の多くは、実際にその方法でうまくいくのかを試してみなければ、結果が分かりません。AIシステム開発も、後ほど詳しく説明するPoCによって試行的に機械学習を実施してみて、うまくいかなければ方針を変更しながら進めていくのが一般的です。また、どちらも、その分野の高度な専門知識がなければ、進めることができません。このように、医師の診療行為とAIシステム開発は、よく似ています。
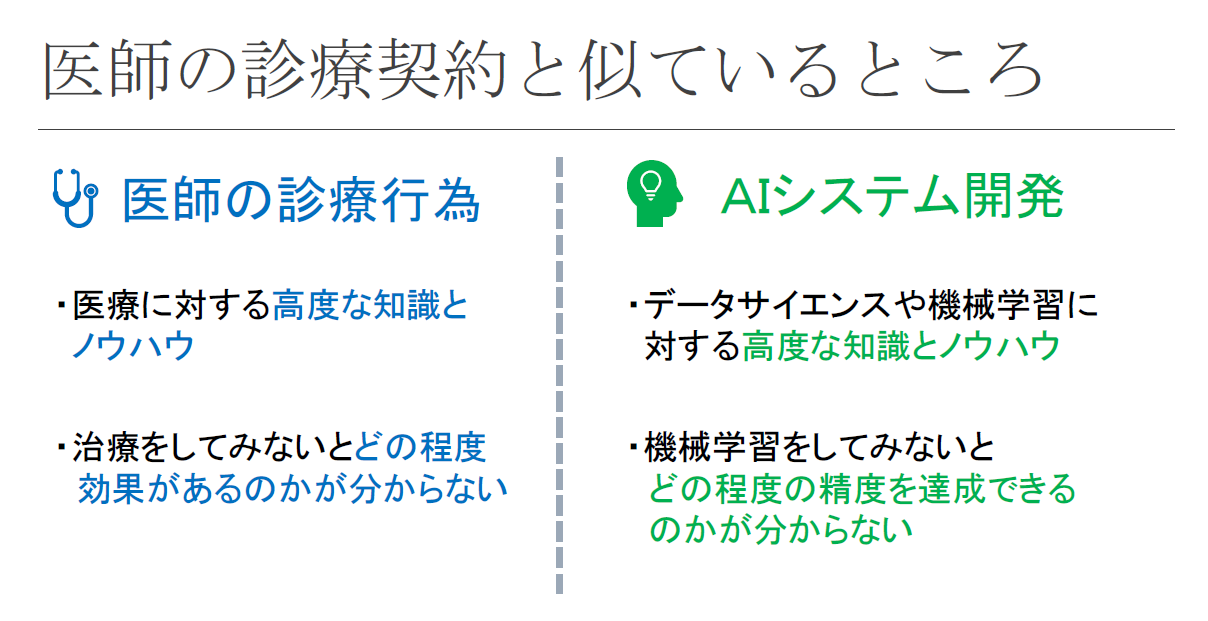
このように、AIシステム開発が医師の診療行為と似ている点を踏まえると、次の2つの視点が見えてきます。
(1)どちらも結果ではなくプロセスの適切さが重視される
(2)どちらも相手の理解力に応じて分かりやすく正確な説明が求められる
では、ここからは、2つの視点を踏まえて、AIのプロジェクトマネジメントのあり方について考えていきましょう。
AIのプロジェクトマネジメント
AIのプロジェクトマネジメントは、(1)企画、(2)トライアル(PoC)、(3)開発、(4)運用というステップで進められることが一般的です。それでは、ここからは、AIのプロジェクトマネジメントにおいてどのようなことに留意しなければならないかを検討します。
企画段階
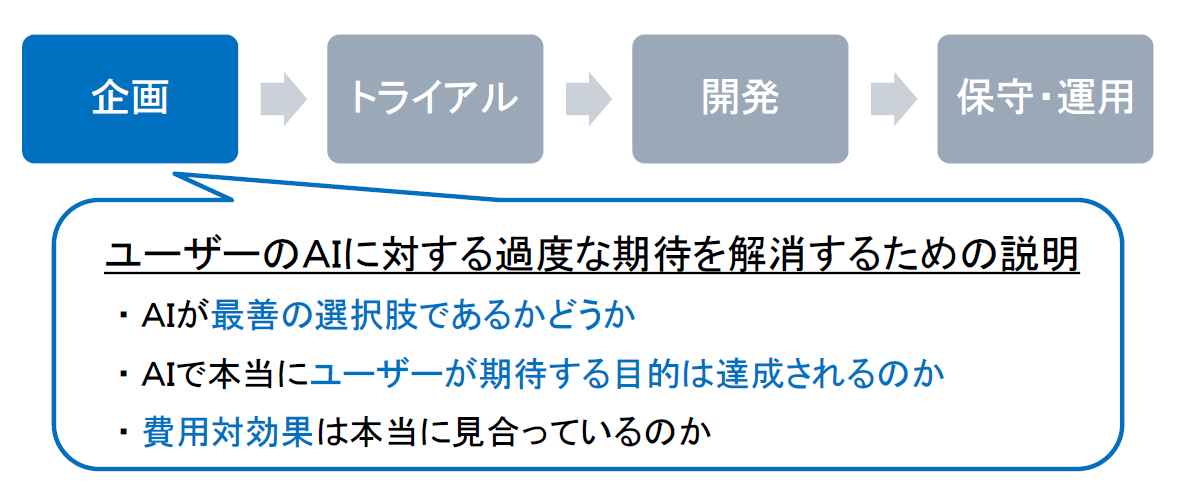
まず、企画段階においては、何よりもユーザーのAIに対する過度な期待を解消するための説明を心がけることが必要です。
ユーザーは、「AIがあれば何でもできる」「AIを導入すればビジネスがうまくいく」という過度な期待を抱いていることがよくあります。特に、最近は、「AI」を活用することが1つのブームのようになっているため、安易にAIを導入して失敗してしまうケースがあります。この点は、ベンダーがユーザーに対して正確な説明を尽くし、誤解を解消しておかなければ、後々になって「なぜリスクを伝えてくれなかったのか」とトラブルになってしまうおそれがあります。医師の診療行為では、リスクのある治療の際にはその点をきちんと説明することが求められるように、AIシステム開発においても、リスクについてはきちんと説明を尽くしておかなければなりません。
第1に、AIの導入が最善の選択肢であるかどうかについて、的確なアドバイスをすることが求められます。例えば、現在保有するデータでは高精度のAIを実現することが難しいのであれば、AIではなく人的リソースを投入することによって課題を解決していくほうが、よりよいビジネスを実現することができると考えられます。
第2に、AIで本当にユーザーが期待する目的を達成することができるのかどうかについても、的確なアドバイスをすることが求められます。AIの精度がどこまで達成されるかについては未知数なところがあり、期待している目的を達成することができないリスクがあることも、きちんと伝えておくべきです。
第3に、費用対効果が合っているのかについても、的確なアドバイスをすることが求められます。AIの実現のために高額なコストを要する場合、AIではなく人的リソースの投入によって課題を解決していくほうが、よりよいビジネスを実現できることがあります。そのような観点についても、ユーザーにはきちんと伝えておくべきです。
トライアル段階
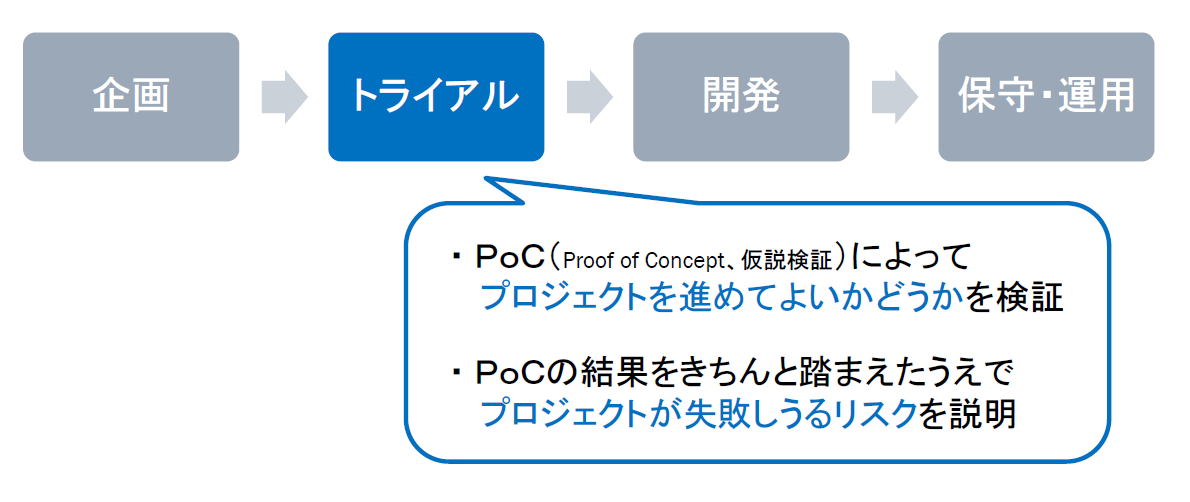
AIシステム開発においては、特に、PoCを適切に進めていくことが重要です。PoCは、ベンダーがその後のプロジェクトを継続してよいかどうかを的確に検証するとともに、その後のプロジェクトを進めるに当たってのリスクを的確にユーザーに説明するために大きな意味があります。PoCのプロセスに問題が合った場合は、その点の法的責任をユーザーから問われるおそれがあります。
ここで、PoCの基本的な流れを確認しておきましょう。
1.データの範囲の決定
実際のAIの運用場面を想定して、PoCに利用するデータの範囲を決定します。
データの範囲を検討するに当たっては、ベンダーの過去の経験やデータサイエンスの知識に基づく専門家としての判断が求められます。
2.データの分析
データの分布の相関性やカテゴライズの必要性など、専門的な知見に基づいてデータを分析し、機械学習に適しているかどうかを検討することが求められます。
3.モデル設計
データの量や性質などを踏まえて、適切なアルゴリズムを選択することが求められます。その際、「ユーザーの意向をかなえるために」という視点も持っておかなければなりません。
4.データの加工
グループ化やラベルづけ、ノイズの除去、データオーグメンテーション、データのサンプリングなど、専門家の視点から的確な作業を実施することが求められます。
5.評価指標の決定
機械学習の精度や、許容できない過学習の程度などの指標を決定します。その際には、ユーザーの意向も踏まえておく必要があります。
まとめ
PoCのプロセスは、以上のとおりです。それぞれのプロセスにおいて、ユーザーの意見を踏まえるべき視点、ユーザーの意見にとらわれずに専門家として客観的に評価すべき視点を適切にすみ分けることが大切です。
事例についての検討
以上のことを踏まえると、今回の事例についてユーザーへの反論を検討するうえでは、次の2つの視点に着目することが適当です。
視点1.ユーザーが期待するAIの精度についてすり合わせがきちんとできていたか
まず、工場において実際に運用する際にどの程度が求められるかについて、ベンダー・ユーザー間で共通認識を持つことができていたかについて、検証が必要です。ベンダーとしては、運用に適した精度を達成することができない可能性があるならば、そもそもプロジェクトを進めてよいかどうかについて、ユーザーときちんとすり合わせを行うべきでした。このようなすり合わせが的確にできていたかについて、検証すべきです。
視点2.PoCにおけるデータの分析や加工方法の検討について不十分な点はなかったか
先ほど説明した視点でPoCを適切に進めて評価を実施することができていたかについて、専門的な知見を踏まえた検討が求められます。
ベンダーとしては、以上の2つの視点を踏まえて問題点を検証し、その結果としてベンダー側に問題がなかったといえるのであれば、ユーザーにその点をきちんと説明して反論すべきです。
ユーザーと契約を締結する際の留意点
ここまで説明したように、一般的なシステム開発とAIシステム開発とでは、知的財産やプロジェクトマネジメントの観点で大きな違いがあります。これまでのシステム開発契約書をAIシステム開発案件に転用することは、リスクが高いことから絶対に避けるべきです。
AIシステム開発の契約書のひな型については、「AI・データの利用に関する契約ガイドライン・AI編」(平成30年6月経済産業省)にモデル契約書がありますので、そちらを参考に用意することをおすすめします。
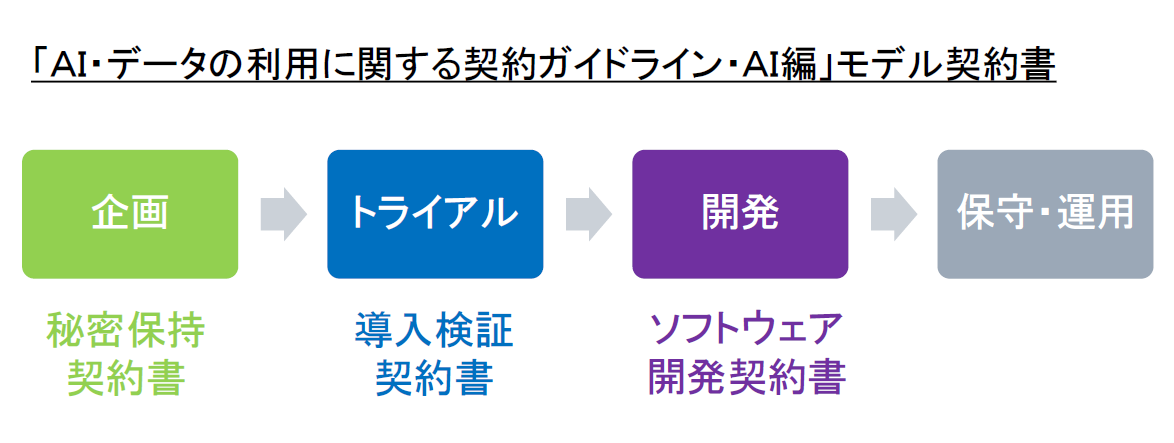
モデル契約書は、企画・トライアル・開発の各プロセスについて用意されています。
ただし、モデル契約書をもとにひな型を作成する際には、次の3つの点に留意すべきです。
留意点1.知的財産権の「共有」はできれば避けたい
知的財産権を共有していると、いざユーザーとの関係が悪化した際に大きな支障が生じます。どうしてもユーザーと折り合いがつかないことから共有関係を選択せざるをえないケースはありますが、できれば共有関係は避けるべきです。
留意点2.知的財産権の帰属について「別途協議」という条項はできれば避けたい
別途協議とは、交渉を先延ばしにすることに他なりません。どうしてもユーザーと明確な合意について折り合いがつかないことからひとまず別途協議という条項を選択せざるをえないケースもあるかもしれませんが、いざユーザーとの関係が悪化した際には協議が困難になることが通常ですので、できればこのような条項は避けるべきです。
留意点3.成果物の利用条件についての取り決めがとても重要
成果物の利用条件をどのようなケースでどのように定めるべきかについて、「AI・データの利用に関する契約ガイドライン・AI編」では明確な答えが示されていません。このコラムの内容を踏まえて、臨機応変な交渉によってユーザーと合意することが必要です。
弁護士をビジネスパートナーとして活用するコツ
AIベンチャーには(特に設立から間がない場合には)、ビジネスやAI技術の知識を有する人員は在席している一方、法務の知識を有する人員が在籍していないケースが多々あります。しかし、このコラムで説明したように、AI開発プロジェクトの成功のためには、ビジネスやAI技術の知識だけではなく、法務の知識も必要不可欠です。
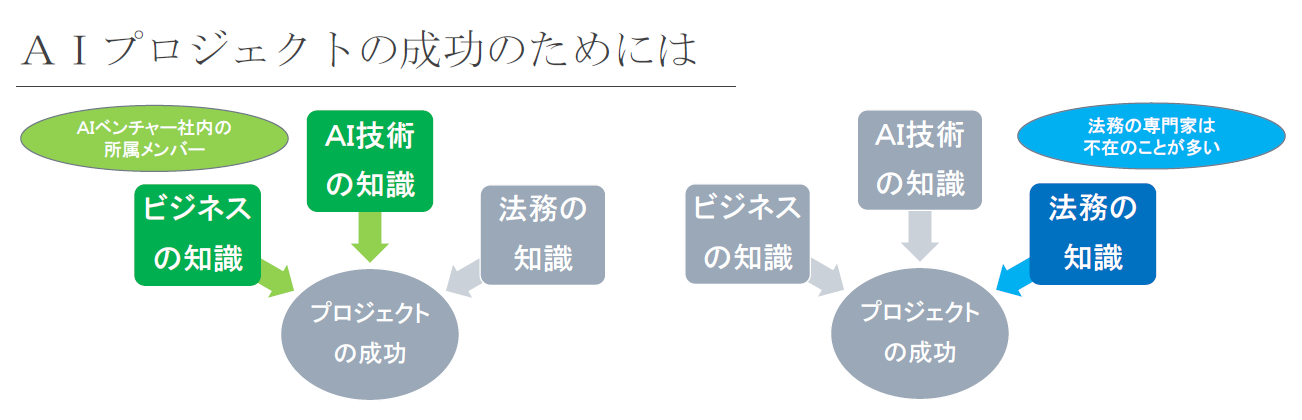 そこで、AIベンチャーにおすすめしたいのが、AI法務の分野を取り扱う弁護士に気軽に相談することができる関係を構築しておくことです。
そこで、AIベンチャーにおすすめしたいのが、AI法務の分野を取り扱う弁護士に気軽に相談することができる関係を構築しておくことです。
弁護士の3つの活用方法
1.ユーザーともめてしまった際の交渉対応
2.有利にユーザーとの交渉を進めるためのアドバイス
3.不利な立場にならないための堅牢な契約書の作成・リーガルチェック
弁護士に相談すべきケースは、法律トラブルが起きてしまった後だけではありません。法律トラブルが起きないための予防法務や、ビジネスをうまくすすめるための戦略法務といった、様々な活用方法があります。
Web Lawyersでも、AIベンチャーをサポートする法務サービスをご提供しています。